Project documentation#
Documenting your project will makes it much easier for others to understand your goal and ways of working, whether you’re developing a package or collaborating on a piece of analysis.
README#
When working on a collaborative or open coding project, it’s good practice to describe an overview of your project in a README file.
This allows users or developers to grasp the overall goal of your project.
As well as a description of the project, it might include examples using your code or references to other associated projects.
This file can be any text type, including .txt, .md, and .rst, and can be associated with your automated documentation.
We suggest the following for a good README:
Short statement of intent.
Longer description describing the problem that your project solves and how it solves it.
Basic installation instructions or link to installation guide.
Example usage.
Screenshot if your project has a graphical user interface.
Links to other project guidance, for example methodological papers or document repositories.
Links to related projects.
Contributing guidance#
When collaborating, it is also useful to set out the standards used within your project. This might include particular packages required for certain tasks and guidance on the code style used in the project. Consider including a code of conduct if you plan to have contributors from outside your organisation. Please see GitHub for advice on creating a code of conduct.
See the CONTRIBUTING file from our gptables package for an example:
# Contributing
When contributing to this repository, please first discuss the change you wish
to make via issue, email, or any other method with the owners before making a change.
## Pull/merge request process
1. Branch from the `dev` branch. If you are implementing a feature name it
`feature/name_of_feature`, if you are implementing a bugfix name it
`bug/issue_name`.
2. Update the README.md and other documentation with details of major changes
to the interface, this includes new environment variables, useful file
locations and container parameters.
3. Once you are ready for review please open a pull/merge request to the
`dev` branch.
4. You may merge the Pull/Merge Request in once you have the sign-off of two
maintainers.
5. If you are merging `dev` to `master`, you must increment the version number
in the VERSION file to the new version that this Pull/Merge Request would
represent. The versioning scheme we use is [SemVer](http://semver.org/).
## Code style
- We name variables using few nouns in lowercase, e.g. `mapping_names`
or `increment`.
- We name functions using verbs in lowercase, e.g. `map_variables_to_names` or
`change_values`.
- We use the [numpydoc](https://numpydoc.readthedocs.io/en/latest/format.html)
format for documenting features using docstrings.
## Review process
1. When we want to release the package we will request a formal review for any
non-minor changes.
2. The review process follows a similar process to ROpenSci.
3. Reviewers will be requested from associated communities.
4. The `dev` branch will only be released once reviewers are satisfied.
Contributing
When contributing to this repository, please first discuss the change you wish to make via issue, email, or any other method with the owners of this repository before making a change.
Pull/merge request process
Branch from the
devbranch. If you are implementing a feature name itfeature/name_of_feature, if you are implementing a bugfix name itbug/issue_name.Update the README.md and other documentation with details of major changes to the interface, this includes new environment variables, useful file locations and container parameters.
Once you are ready for review please open a pull/merge request to the
devbranch.You may merge the Pull/Merge Request in once you have the sign-off of two maintainers.
If you are merging
devtomaster, you must increment the version number in the VERSION file to the new version that this Pull/Merge Request would represent. The versioning scheme we use is SemVer.
Code style
We name variables using few nouns in lowercase, e.g.
mapping_namesorincrement.We name functions using verbs in lowercase, e.g.
map_variables_to_namesorchange_values.We use the numpydoc format for documenting features using docstrings.
Review process
When we want to release the package we will request a formal review for any non-minor changes.
The review process follows a similar process to ROpenSci.
Reviewers will be requested from associated communities.
Only once reviewers are satisfied, will the
devbranch be released.
In this case we have outlined our standard practices for using version control on GitHub,
the code style that we are using in the project and the review process that we follow.
We have used the Markdown (.md) markup language for this document,
which is formatted into HTML when viewed on our repository.
User desk instructions#
If your project is very user focused for one particular task, for example, developing a statistic production pipeline for other analysts to execute, it is very important that the code users understand how to appropriately run your code.
These instructions should include:
How to set up an environment to run your code (including how to install dependencies).
How to configure the project, for example how to set folders and environment variables if you use them.
How to run your code.
What outputs (if any) your code or system produces and how these should be interpreted.
What quality assurance has been carried out and what further quality assurance of outputs is required.
How to maintain your project (including how to update data sources).
Dependencies#
The environment that your code runs in includes the machine, the operating system (Windows, Mac, Linux…), the programming language, and any external packages. It is important to record this information to ensure reproducibility.
The simplest way to document which packages your code is dependent on is to record them in a text file.
We typically call this text file requirements.txt.
Python packages record their dependencies within their setup.py file, via setup(install_requires=...).
You can get a list of your installed python packages using pip freeze in the command line.
R packages and projects record their dependencies in a DESCRIPTION file.
Packages are listed under the Imports key.
You can get a list of your installed R packages using the installed.packages() function.
You will find environment management tools, such as
renv for R or
pyenv for python useful for keeping track of software and package versions used in a project.
Citation#
It can be helpful to provide a citation template for research or analytical code that is likely to be referenced by others.
You can include this in your code repository as a CITATION file or part of your README.
For example, the R package ggplot2 provides the following:
To cite ggplot2 in publications, please use:
H. Wickham. ggplot2: elegant graphics for data analysis. Springer New York,
2009.
A BibTeX entry for LaTeX users is
@Book{,
author = {Hadley Wickham},
title = {ggplot2: elegant graphics for data analysis},
publisher = {Springer New York},
year = {2009},
isbn = {978-0-387-98140-6},
url = {http://had.co.nz/ggplot2/book},
}
If your project includes multiple datasets, pieces of code or outputs with their own DOIs, this might include multiple citations.
See this GitHub guide for more information on making your public code citable.
Vignettes#
Vignettes are a form of supplementary documentation, containing applied examples that demonstrate the intended use of the code in your project or package.
Docstrings may contain examples applying individual functional units, while vignettes may show multiple units being used together.
We use the term vignette with reference to R packages, for example this introduction to the
dplyr package for data manipulation.
However, the same long-form documentation is beneficial for projects in any programming language - for instance the
pandas basics guide.
We’ve seen that docstrings can be used to describe individual functional code elements. Vignettes demonstrate the intended use for these classes and functions in a realistic context. This shows users how different code elements interact and how they might use your code in their own program.
Another good example is this vignette describing how to design vignettes in Rmarkdown. You can produce this type of documentation in any format, though Rmarkdown is particularly effectively at combining sections of code, code outputs, and descriptive text.
You might also consider providing examples in an interactive notebook that users can run for themselves.
Versioning#
Documenting the version of your code provides distinct points of reference in the code’s development. Recording the version of code used for analysis is important for reproducing your work. Combining versioning with Version control allows you to recover the exact code used to run your analysis, and thus reproduce the same results.
Semantic versioning provides useful rules for versioning releases of your code. Follow these rules to help other users of your code understand how changes in your code may affect their software. Each level of version number indicates the extent of changes to the application programming interface (API) of your code, i.e., the part of the code that a user interacts with directly. Changes to the major version number indicate changes to the API that are not compatible with use of previous versions of the code. While changes to the minor and patch numbers indicate changes that are either compatible or have no effect on the use of the code, respectively.
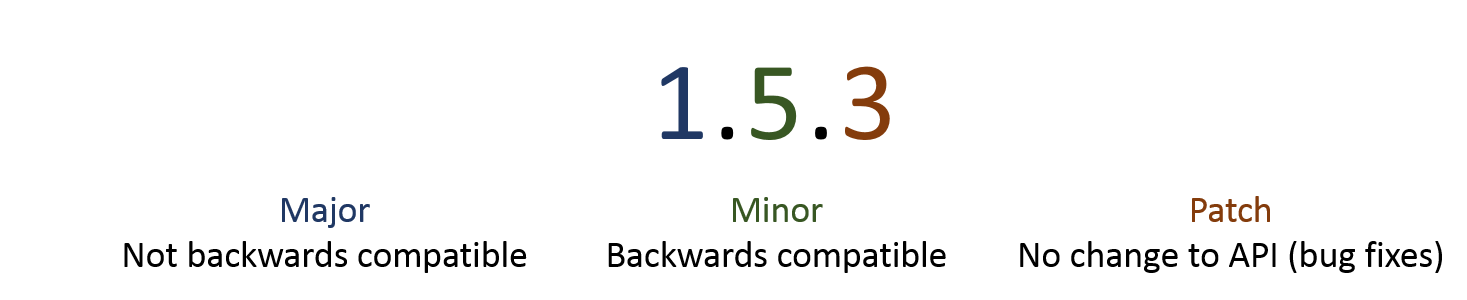
Fig. 5 Semantic versioning#
You’ll see this, or a similar version numbering, on packages that you install for Python and R.
Changes to this book don’t cause backwards-compatibility issues in the same sense as code. We’ve chosen to use a form of calender versioning (CalVer). You’ll see the current version below the site’s table of contents, where the first four digits represent the year that latest changes were made. The incremental number following the full stop indicates how many versions of the guidance have been published in that year. As this guidance will change over time, this version number provides users with a reference for citing a specific state of the guidance.
Changelog#
A changelog records the major changes that have occurred to a project or package between versioned releases of the code.
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## [1.0.0] - 2020-01-21
### Added
- `add_to_each_in_list()`
- online sphinx-generated documentation
- contribution guide
### Removed
- `subtract_to_each_in_list()`
### Changed
- Improved function documentation
### Fixed
- bug in `multiple_each_in_list()`, where output was not returned
Like versioning, users find a changelog is useful to determine whether an update to your code is compatible with their work, which may depend on your code. It can also document which parts of your code will no longer be supported in future version and which bugs in your code you have addressed. Your changelog can be in any format and should be associated with your code documentation, so that it is easy for users and other contributors to find.
keep a changelog provides a simple but effective template for recording changes to your code.
Copyright and Licenses#
Copyright indicates ownership of work. All material created by civil servants, ministers, government departments and their agencies are covered by Crown copyright. It is not essential to include a copyright notice on your work, but doing so can help to avoid confusion around ownership. We recommend including one in government projects.
Licenses outline the conditions under which others may use, modify and/or redistribute your work. As such, including a license with code is important for users and other developers alike. This online tool might help you to choose an appropriate license for your project. The Government Digital Service generally recommends using the MIT license for code and the Open Government License (OGL) for documentation.
Both copyright and license are usually placed in a LICENSE file in your project. For example, an MIT LICENSE file might look like:
Copyright 2020, Crown copyright
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Open source your code#
In government, we support and promote open source whenever possible. Open source software is software with source code that anyone can freely inspect, modify and enhance. As a government analyst, you should aim to make all new source code open, unless you can justify witholding part of your source code.
Open sourcing code benefits you, other government analysts, and the public.
Personal benefits from open sourcing include:
Attribution - coding in the open creates a public record of your contributions to analysis and software.
Collaboration - you can gain experience working with analysts in other departments.
Review - peers and experts in the field can provide advice on improving your analysis and coding.
Feels good - we regularly benefit from open source software, so it’s nice to give something back.
While the public benefit from:
Transparency - stakeholders can understand and reproduce our analysis, which is a core element of the Statistics Code of Practice.
Sharing value - others can benefit from our work, either through reuse or demonstration of good practices.
Sharing opportunity - others can gain insight and experience from reading and possibly contributing to your code.
Please see the Government Data Service (GDS) guidance for help deciding when code should be open or closed. Further GDS guidance addresses security concerns for coding in the open. Additional guidance on deciding when and how to open source, the benefits, and good practice is available from the Analysis Function.